リリースノート
このページには、最新のリリースノートが掲載されています。
目次
- 開発中
- V5.5.0 2024年11月10日
- V5.4.1 2024年6月11日
- V5.4.0 2024年6月6日
- V5.3.4 2024年1月18日
- V5.3.3、2023年10月5日
- V5.3.2、2023年7月11日
- V5.3.1、2023年4月1日
- V5.3.0、2022年12月22日
- V5.2.0、2022年7月6日
- V5.1.0、2022年3月1日
- V5.0.1、2022年1月7日
- V5.0.0、2021年11月30日
- V4.1.3、2021年11月15日
- V4.1.2、2021年11月14日
- V4.1.1、2019年12月26日
- V4.1.0、2019年7月7日
- V4.0.0、2018年10月29日
- V3.05.02、2018年6月19日
- V3.05.01、2017年6月1日
- V3.05.00、2017年2月16日
- V3.04.01、2016年2月16日
- V3.04.00、2015年7月11日
- V3.03(rc1)、2014年2月4日
- V3.02.02、2012年10月23日
- V3.01、2011年10月21日
- V3.00、2010年9月30日
- V2.04、2009年6月30日
- V2.03、2008年4月22日
- V2.02、2008年4月21日
- V2.01、2007年8月30日
- V2.00、2007年7月18日
- V1.04、2007年5月15日
- V1.03、2007年2月3日
- V1.02、2006年10月4日
- V1.01、2006年9月7日
- V1.00、2006年6月17日
開発中
Tesseract の API/ABI 変更に関するレビュー

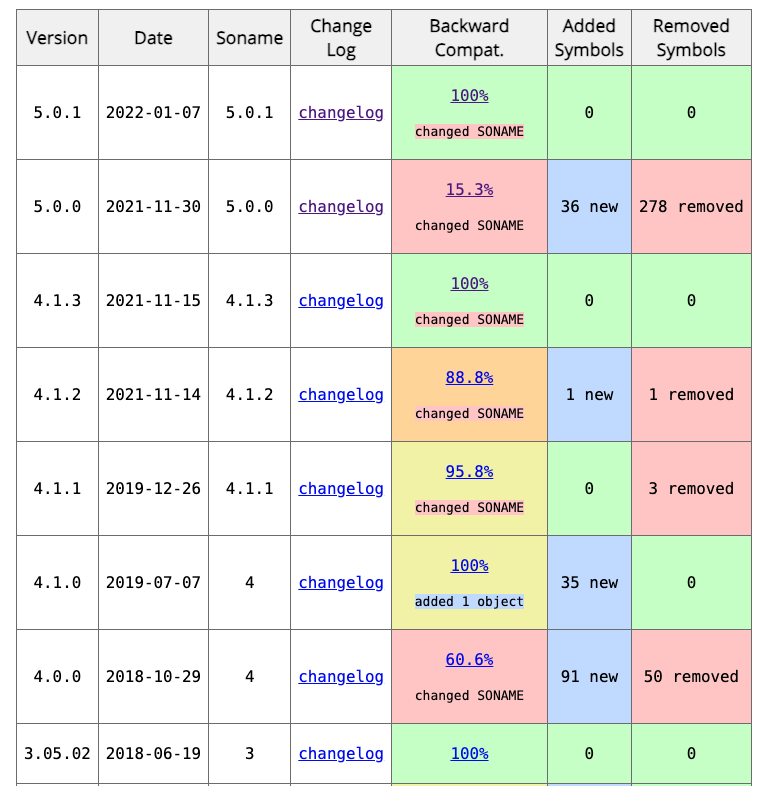
V5.5.0
2024年11月10日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.5.0
V5.4.1
2024年6月11日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.4.1
V5.4.0
2024年6月6日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.4.0
V5.3.4
2024年1月18日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.3.4
V5.3.3
2023年10月5日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.3.3
V5.3.2
2023年7月11日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.3.2
V5.3.1
2023年4月1日
フォーマットをわずかに調整することで、DebugDump 出力を改善しました。PR #4022 で @GerHobbelt が担当。
バグ修正
- ゼロ除算による浮動小数点例外を修正 (issue #3995)。PR #3996 で @stweil が担当。
- issue #3997 および #4010 を修正。レガシーエンジンがコンパイル時に無効になっている場合に誤って無効になっていたいくつかのコードブロックを有効化しました。PR #4041 で @amitdo が担当。
<cstdint>をインクルードすることで、GCC 13 でのビルドを修正しました。PR #4009 で @kraj が担当。
CMake ビルドシステム
- icu と pango のリンクを修正しました。PR #4006 で @autoantwort が担当。
- (MSVC デバッグ) 生成されたファイル
tesseract.pcのライブラリ名を修正しました。PR #4008 で @autoantwort が担当。 - 生成されたファイル
tesseract.pcの libdir を修正しました。PR #4013 で @ferdnyc が担当。
コンパイラサポート
GCC および libstdc++ 8.x のサポートを終了しました。
V5.3.0
2022年12月22日
LSTM トレーニング:関数 BoxFileName を拡張して、別の画像名拡張子 .raw.png を処理できるようにしました。PR #3962 で @bertsky が担当。
バグ修正
- レガシー OCR エンジンのトレーニングツールを修正しました (issue #3925)。PR: #3970、#3972、#3977 で @stweil が担当。
- PDF レンダラー:テキスト以外のブロックを無視する (issue #3957 を修正)。@amitdo が #3959 で担当。
- 閾値処理の前にカラーマップを削除する (issue #3940 を修正)。@zdenop が担当。
- Coverity Scan によって報告されたいくつかのパフォーマンスの問題を修正しました。PR #3967 で @stweil が担当。
- トレーニングツール:
main関数でexit関数の呼び出しを return ステートメントに置き換えました。PR #3878 で @stweil が担当。 - 関数
vigorous_noise_removalの二重解放を修正しました (issue #3876)。コミットee34b100bfで @stweil が担当。 Textord::make_spline_rowsで必要に応じてto_winを作成しました (issue #3875 を修正)。コミット99d6717c10で @stweil が担当。ScrollView::MessageReceiverのメモリの問題を修正しました (issue #3869)。PR #3872 で @p12tic が担当。SVNetwork::SVNetworkで潜在的なnullptrをキャッチしました。コミット02e834000cで @stweil が担当。- 関数
ObjectCache::DeleteUnusedObjectsを近代化しました (サニタイザーの問題を修正)。PR #3978 で @stweil が担当。
ビルドシステム
svpaint.cppをsrc/viewerからsrc/に移動しました。Autotools に svpaint 実行ファイルのルールを追加しました。- FreeBSD での Autotools を使用した AMD64 検出を修正しました。
- CMake から生成された
tesseract.pcを Autotools に合わせるように修正しました。
V5.2.0
2022年7月6日
- Intel AVX512F の初期サポートを追加しました。これにより、「best」モデルを使用した認識とトレーニングのパフォーマンスが向上します。
- C API:メモリからトレーニング済みデータを使用して Tesseract を初期化する関数を追加しました。
- 新しいパラメーター
invert_thresholdを追加しました。デフォルト値は0.7です。以前の 5.x バージョンでは、反転閾値は0.5であり、ユーザーが変更する方法がありませんでした。tessedit_do_invertパラメーターは非推奨となり、バージョン 6.0 で削除される予定です。テキスト行の反転を完全に無効にするには、invert_threshold値を0.0に設定できます。 - UZN ファイルでの回帰を修正しました。
- Leptonica 内部データ構造への直接アクセスを関数呼び出しに置き換えました(これは、次の Leptonica リリースとの互換性のために必要です)。
std::regexをstd::string関数に置き換えました (issue #3830)。- 32 ビットホスト上の非常に大きな PDF ファイルに対する修正。
- 一部のバージョンの 32 ビット MSVC コンパイラでコンパイルする場合、AVX2 コードに
/Osを設定します (issue #3769)。 - Windows でもコンパイル時に組み込まれた
TESSDATA_PREFIXを使用します。 - C API:
mallocで割り当てられたメモリに対してdelete[]を呼び出すことを修正しました。 - CI ビルド定義を改善しました。
- Autotools および CMake ビルド定義を改善しました。
V5.1.0
2022年3月1日
- ALTO、hOCR、テキスト出力形式で画像および行区切り領域を処理します。
- その他のいくつかの機能強化。
- 少数のバグ修正。
- 使用されていないコードを削除しました。
- 必要な最小 CMake バージョンを 3.10 に上げました。
V5.0.1
2022年1月7日
- GCC 11 を使用した msys2 ビルドの修正。
- URL で OCR を実行する場合、最大 8 つのリダイレクトをサポートします。
STATS::pile_count()でnullptrをキャッチします。NetworkIO::ZeroTimeStepGeneral()を削除しました。これにより、より多くのインラインコードが可能になります(最適化)。- ルックアップテーブルのジェネレーターを更新して、
doubleの代わりにTFloatを使用します。 functions.hの clang コンパイラ警告を修正しました。新しいコードではdoubleとfloatの間の変換が回避されるため、パフォーマンスにもわずかにプラスの効果があるはずです。- コンパイラ警告 [
-Wsign-compare] を修正しました。 - 空のステートメントによって発生したコンパイラ警告を修正しました。
- その他のいくつかのコンパイラ警告を修正しました。
- 使用されていないコードを削除しました。
- パブリックインクルードファイルに
SPDX-License-Identifierを追加しました。
CMake ビルド
amd64、x86_64、i386、i686ターゲットを正しく検出します。- pkg-config が存在しない場合、トレーニングツールの構成を試行しません。
- Tesseract 構成ファイルをインストールします。
V5.0.0
2021年11月30日
- 大幅なパフォーマンス向上
- LSTM モデルのトレーニングとテキスト認識に
float(32 ビット) をサポートしました。floatは、double(64 ビット) の代わりにデフォルトになりました。これは、RAM 消費量の削減とプログラム実行速度の向上を意味します。 - 平均信頼度が 50% 未満の場合のみ、反転行で OCR を試行します (#3141)。
- SIMD
- Arm Neon の手動ドット積サポートを追加しました。
- その他多くの改善。
- LSTM モデルのトレーニングとテキスト認識に
- 一般的な機能強化
- Leptonica ベースの新しい 2 つの二値化方法を追加しました:Adaptive Otsu と Sauvola。ユーザー向け:関連する構成可能なパラメーターを確認するには
tesseract --print-parameters | grep thresholding_を使用してください。 - テーブル検出機能と干渉するため、楽譜検出と削除を無効にしました。
pageseg_apply_music_maskのデフォルト値をfalseに変更しました。 - 新しいコマンドラインオプション
--print-fonts-tableを追加しました。フォントのリスト (ID、名前) を出力します。レガシー OCR エンジンのデータを持つトレーニング済みデータファイルにのみ適用可能です。 - 新しいパラメーター
tessedit_font_idを追加しました。これを使用して、Tesseract にトレーニング済みデータファイルから特定のフォントを使用して画像内のテキストを認識させることができます。 - 新しいコマンドラインオプション
--loglevelを追加しました。 - LSTM エンジンでトレーニングされたトレーニング済みデータのネットワーク仕様を取得するための
combine_tessdataに新しいオプション-lを追加しました。 lstmtrainingツール:--max_iterationsの負の値をエポックとして解釈します。- NFKC 正規化から NFC 正規化に切り替えました (分解モードが要求されている場合は NFKD から NFD に切り替えます)。
- テキスト出力:1ページの画像にはページ区切りを追加しないでください。
- hOCR出力:
scan_resプロパティをocr_pageに書き込みます。 - 以前のリリースでは、PDFレンダリングに
pdf.ttfが必要でした。5.0.0では、このファイルは不要になりました。疑似フォントはコードに埋め込まれています。
- Leptonica ベースの新しい 2 つの二値化方法を追加しました:Adaptive Otsu と Sauvola。ユーザー向け:関連する構成可能なパラメーターを確認するには
- コードの近代化
- 公開APIからカスタムデータ型
STRING、GenericVector、PointerVectorを削除しました。STRING型はコードベースから完全に削除され、std::stringに置き換えられました。GenericVector型は、コードベースの大部分でstd::vectorに置き換えられました。PointerVectorは部分的にstd::vectorに置き換えられました。 - カスタム
BITS16の代わりにstd::bitset<16>を使用します。 - mallocとfreeを最新のC++コードに置き換えます。
strdupとfreeをstd::stringに置き換えます。- いくつかの
snprintfをstd::to_stringに置き換えます。 - Cスタイルの型キャストをC++スタイルの型キャストに置き換えます(
-Wold-style-castコンパイラ警告を修正)。不要な型キャストを削除します。 - typedef structをstructに置き換えます。
- カスタム関数ではなく
std::swapを使用します。 - より多くの場所で
unique_ptr/make_uniqueを使用します。 - clang-tidyを使用してコードを近代化します。
- コードベースを近代化するためのその他多くの変更が行われました。
- 公開APIからカスタムデータ型
- トレーニングスクリプト
- Bashベースのトレーニングスクリプトを削除しました。これらのスクリプトが必要な場合は、リポジトリ履歴で見つけることができます。これらの古いサポートされていないスクリプトに関する新しい問題を開かないでください。
- Pythonベースのトレーニングスクリプトをtesstrainリポジトリに移動しました。
- ビルドシステム
- Autotoolsビルドをリファクタリングしました。非再帰的(auto)makeを使用するようになりました。
- configure.ac:必要な最小のautoconfバージョンを2.69に更新しました。
- 必要な最小のPangoバージョンを1.38.0に上げました。
- libtesseract API
- このリリースには、公開APIに大きな変更が含まれています。バージョン5.0.0は4.xと互換性がありません。libtesseractを使用している開発者は、コードをこれらの変更に適応させる必要があります。
- 公開ヘッダーの数を減らしました。これには、
genericvector.hとstrng.hヘッダーファイルが含まれます。 - APIから不要なメソッドをいくつか削除しました。
- ソースコードレイアウトの再編成、ファイルの改名
- すべての公開ヘッダーは、
include/tesseractディレクトリに配置されるようになりました。 tess_version.h.inをversion.h.inに改名しました。platform.hをexport.hに改名しました。src/api/tesseractmain.cppをsrc/tesseract.cppに移動しました。src/trainingディレクトリ:トレーニングツールとライブラリを分離しました。
- すべての公開ヘッダーは、
- 更新された要件
- ソースコードからTesseractをビルドするには、C++17を適切にサポートするコンパイラが必要です。
V4.1.3
2021年11月15日
壊れたautotoolsビルドを修正しました。
V4.1.2
2021年11月14日
RowAttributes()をLTRResultIteratorからPageIteratorに移動しました。- トレーニング対象の画像の最大許容幅を
2560から4096に変更しました。 - システムオブジェクトのリークを防ぐために、
SVMutexとSVSemaphoreのデストラクタを追加しました。 - 空のALTO
sourceImageInformationを出力しません。 - libcurlを使用して、TesseractのURIサポートを拡張しました。
- 整数モデルを使用して実行されたLSTMトレーニングプロセスについて警告し、停止します。
Autotoolsビルドの変更
- MacOSのautoconfビルドを修正しました。
DEFAULT_INCLUDESの再定義によるautomake警告を修正しました。- autoconfビルドで
-march=native -mtune=nativeコンパイラフラグを使用しません。 - デフォルトでautomakeビルドのノイズを低減しました。
V4.1.1
2019年12月26日
- URLによる画像または画像リストのサポートを追加しました。この機能はlibcurlを使用して実装されています。使用方法:
tesseract http://IMAGE_URL OUTPUT ... - OCR出力ファイル(hOCR、PDF、ALTO)にタイトルを設定するためのパラメーター
document_titleを追加しました。 falseに設定すると、tesseractの実行速度を向上させることができるパラメーターtessedit_do_invertを追加しました。- 音楽マスクの無効化を許可するパラメーター
pageseg_apply_music_maskを追加しました。 - hOCRレンダラーとより一致させるために、ALTOレンダラーにComposedBlockレベルを追加しました。
- トレーニング:より多くの画像名(
.bin.pngと.nrm.png)を処理できるように関数BoxFileNameを拡張しました。PR #2686。 - 4.1.0以降に見つかったロケール処理の問題をさらに修正しました。
- text2imageのメモリリークを修正しました。
- UndefinedBehaviorSanitizerを実行することで発見された潜在的なバグを修正しました。
- Coverity Scanによって報告された多くの問題を修正しました。
- コードのクリーンアップと近代化。
- コードの最適化。
- 多くのバグ修正。
- swビルドシステムとパッケージマネージャーを使用してtesseractをビルドするオプションを追加しました。cppanを使用したビルドは非推奨になりました。
V4.1.0
2019年7月7日
- 4.0.0と下位互換性のあるリリース
- 設定可能な変数
dotproductを使用してドット積関数を選択するオプションを追加しました。可能な値:auto(デフォルト)、generic、native、avx、sse。 - ALTO標準でフォーマットされた新しい出力オプションを追加しました。コマンドラインの使用法:
tesseract imagename outputbase alto。この出力は**実験的**であり、次のリリースまでに少し変更される可能性があります。 - トレーニングを簡素化するために、新しいレンダラーLSTMBox、WordStrBoxを追加しました。
- hOCR出力に文字ボックスを追加しました。
- 代替シェルスクリプトとして、Pythonトレーニングスクリプト(実験的)を追加しました。
- ロケール処理の問題を修正しました。libtesseractは、どのロケールでも動作するようになりました。
- AVX / AVX2 / SSEのサポートを改善しました。
- バウンディングボックスの問題に対する修正。
- LSTMエンジンでホワイトリスト/ブラックリストのサポートを実装しました。
- LSTMエンジンでuser-wordsファイルとuser-patternsファイルが動作するようにしました。#2328
- コードの近代化と改善。
- 多くのバグ修正。
- CMake構成の改善。
- デフォルトでOpenMPサポートを無効にしました。これはCMakeビルドでは行われましたが、AutotoolsビルドではOpenMPは依然としてデフォルトで有効になっています(例:#1171、#1081を参照)。
V4.0.0
2018年10月29日
- 新しいOCRエンジン
- LSTMに基づくニューラルネットワークシステムを使用する新しいOCRエンジンを追加し、精度が大幅に向上しました。
- これには、LSTM OCRエンジンの新しいトレーニングツールが含まれています。新しいモデルは、既存のモデルを最初からトレーニングするか、ファインチューニングすることでトレーニングできます。
- 123言語のLSTMモデルを含むトレーニング済みデータを追加しました。
- LSTM認識器のオプションの高速化されたコードパスを追加しました。
- OpenMPを使用
- SIMDを使用:AVX2 / AVX / SSE4.1
- hOCR出力に代替記号の選択肢を含めることができる新しいパラメーター
lstm_choice_modeを追加しました。
- その他のOCRエンジン
- 以前のバージョンで主要なOCRエンジンであったパターンマッチングOCRエンジンは、このバージョンでも引き続き使用できます。
- コードベースから「Cube」OCRエンジンを削除しました。これは、ヒンディー語とアラビア語で使用されていました。新しいLSTMエンジンの方がはるかに優れたパフォーマンスを発揮するため、Cubeエンジンは不要になりました。
- 更新されたビルドシステム
- Tesseractは、セマンティックバージョニングを使用するようになりました。
- レガシーOCRエンジンのコードなしでTesseractをコンパイルするオプションを追加しました。
- 更新された要件
- ソースコードからTesseractをビルドするには、C++11を適切にサポートするコンパイラが必要です。
- Tesseractは、Leptonica 1.74.0以降のバージョンを必要とするようになりました。
- 必要な最小のautoconfバージョンを2.63に更新しました。
- トレーニングツールの依存関係-必要な最小バージョンを更新しました:ICU 52.1、Pango 1.22.0。
- バグ修正と機能強化
- コンパイラ警告をトリガーした多くの問題を修正しました。
- Coverity ScanまたはLGTMによって報告された多くの問題を修正しました。
- トレーニングデータレンダリングの修正。
- PDFの処理時のバイナリ画像への損傷を修正しました。
- リリースコードの致命的なエラーに対して意図的なセグメンテーションフォルトをトリガーしません(コミット5338a5a8d)。
- OpenCLコードのいくつかの問題を修正しました。OpenCLはレガシーTesseract OCRエンジンでは動作しますが、パフォーマンスは向上しません。LSTM OCRエンジンでは実装されていません。
- 複数ページのTIFF処理を改善しました。
- PDFレンダリングの改善。
- トレーニングツールにバージョン情報と改善されたヘルプテキストを追加しました。
- log2()の高速バージョンを追加しました。
tesseractマニュアルページで、画像のリストを含む入力テキストファイルを使用するオプションについて説明しました。- psm 0が要求された場合、デフォルトのトレーニングデータとして「osd」を使用しました(現在、この機能はコマンドラインインターフェースでは実装されていますが、APIでは実装されていません)。
- hocr、pdf、tsv構成ファイルから
tessedit_pageseg_mode 1を削除しました。ユーザーは、それが必要な場合は--psm 1を明示的に使用する必要があります(コミットecfee53ba)。 - 使用可能な言語とスクリプトのリストは、アルファベット順に並べ替えられるようになりました。
- パラメータ
unlv_tilde_crunchingはfalseに変更されました。これは、値がtrueの場合、Tesseract 4 で問題が発生するためです(#948、#1449)。 - パラメータを追加しました:
min_characters_to_try。
- その他。
- Tesseract のソースツリーを再構成しました。ほとんどのソースコードは現在
srcディレクトリ以下にあります。 - メインリポジトリに単体テストを追加しました。単体テストには、Git サブモジュールとトレーニング用のコードが必要です。
- 廃止されたコードを削除しました。
- Tesseract のソースツリーを再構成しました。ほとんどのソースコードは現在
- 重要な注意事項
- 新しい LSTM エンジンはまだ、古いレガシーエンジンからのすべての機能をサポートしていません(欠落している機能を参照)。
- Tesseract は現在、「C」ロケールを必要としています。これは、Java や Python などのプログラミング言語からライブラリとして Tesseract を使用する際に主に影響します。ロケールとは、言語(または言語バリアント)または国に依存する複数の設定を表します。これらの設定の中には、記号の分類(例:「この文字は空白文字ですか?」)や数値の表示方法(例:「3.141」または「3,141」)を決定するものがあります。現在の Tesseract コードは暗黙的にいくつかの固定された設定を期待しており、そうでない場合は失敗します。したがって、設定が確実に機能しないと判断できない場合、コードはアサーションで開始直後に失敗します。デフォルトで適切な設定を含む「C」ロケールを取得する C または C++ プログラムでは、これは問題になりません。その他のすべてのユースケースでは、現在、Tesseract コードを実行する前に「C」ロケールに切り替える必要があります。修正済み(バージョン 4.1.0)。
V3.05.02
2018年6月19日
このリリースでは、4.0.0 からバックポートされたいくつかのバグを修正しました。
V3.05.01
2017年6月1日
- PDF 出力に対して、非表示のテキストレイヤーのみ(完全な入力画像なし)をレンダリングするオプションを追加しました。
- GenericVector にいくつかの最適化を行いました。
- –disable-graphics ビルドを修正しました。
- –enable-visibility ビルド(トレーニングツールを含む)を修正しました。
- 改行として ‘\r\n’ を使用する設定ファイルの読み込みを修正しました。
- OpenCL - 一部の問題を修正しました。コードの大部分を削除しました。
- デッドコードを削除しました。
V3.05.00
2017年2月16日
- Tesseractは、Leptonica 1.74.0以降のバージョンを必要とするようになりました。
- hOCR 出力に微調整を行いました。
- 別のオプションの出力形式として TSV を追加しました。
- AnalyseLayout() メソッドで 3.04.00 で導入された ABI ブレイクを修正しました。
- text2image ツール - フォントで使用可能なすべての OpenType リガチャを有効化します。この機能には、Pango 1.38 以降が必要です。
- トレーニングツール - アサーションを tprintf() と exit(1) に置き換えました。
- Cygwin の互換性を修正しました。
- 複数ページの TIFF 処理を改善しました。
- 埋め込み PDF フォント (pdf.ttf) を改善しました。
- コマンドラインから OCR エンジンのモードを選択できるようにしました。
- Tesseract のコマンドラインパラメータ ‘-psm’ を ‘–psm’ に変更しました。
- 方向とスクリプト検出のための新しい C API を追加し、古いものを削除しました。
- 最小の autoconf バージョンを 2.59 に上げました。
- デッドコードを削除しました。
- 多くのコンパイラの警告を修正しました。
- メモリリークとリソースリークを修正しました。
- 「Cube」OCR エンジンに関するいくつかの問題を修正しました。
- いくつかの OpenCL の問題を修正しました。
- CMake ビルドシステムを使用して Tesseract をビルドするオプションを追加しました。
- Windows のビルドを容易にするため、CPPAN サポートを実装しました。
V3.04.01
2016年2月16日
- psm 0 の OSD レンダラーを追加しました。単一ページと複数ページの画像で動作します。
- tesstrain.sh スクリプトを改善しました。
- ScrollView のビルドと実行を簡素化しました。
- OS X Preview ユーティリティの PDF 出力を改善しました。
- hOCR 行高さ情報に対する非互換性の修正 - コミット 134ebc3。
- Cube OCR エンジンなしで Tesseract をビルドするオプションを追加しました (-DNO_CUBE_BUILD)。
- このプロジェクトでは、Travis CI と AppVeyor の継続的インテグレーションサービスを使用しています。
V3.04.00
2015年7月11日
- Tesseract の開発は現在、Git を使用して github.com でホストされています(以前は Subversion を VCS として、code.google.com をホスティングに使用していました)。
- Tesseract は現在、Leptonica 1.71 以降のバージョンが必要です。
- VS2008 の公式サポートを削除しました。
- 100 言語での広範なテストの結果として、トレーニングシステムに大きな更新を行いました。
- 100 以上の言語の新しいトレーニングデータ 100以上の言語。39 の追加のスクリプト/言語のサポートを追加しました: amh, asm, aze_cyrl, bod, bos, ceb, cym, dzo, fas, gle, guj, hat, iku, jav, kat, kat_old, kaz, khm, kir, kur, lao, lat, mar, mya, nep, ori, pan, pus, san, sin, srp_latn, syr, tgk, tir, uig, urd, uzb, uzb_cyrl, yid。
- 大きなドキュメントでプライマリが満杯になった場合に引き継ぐバックアップ適応分類器を追加しました。
- PIC コンパイルオプションのパフォーマンスを向上させました。
- 特に ghostscript などの外部プログラムとの互換性を向上させるために、PDF 出力における非表示フォントシステムに大きな変更を加えました。
- フォント識別を改善しました。
- タイ語、ベトナム語、カンナダ語、テルグ語など、多くのアクセント記号を使用する言語のレイアウト分析を改善するための大きな変更を行いました。
- ずれたベースラインの問題を修正したため、認識はレイアウト分析のエラーから回復できます。
- ヒープチェッカーを実行する場合、特に難しい画像での速度を向上させるための大きなリファクタリングを行いました。
- ページレイアウトのグローバルから tesseractclass にパラメータを移動しました。
- 単一列のレイアウト分析を改善しました。
- Tesseract コマンドライン実行可能ファイルを使用して、複数の形式で OCR 出力を許可しました。
- eng+ara スクリプトが混在している場合の問題を修正しました。
- 数値におけるスクリプトの一貫性を改善しました。
- 行認識を有効にするために、control.cpp を大幅にリファクタリングしました。
- メインのトレーニングスクリプトである tesstrain.sh を追加しました。
- text2image トレーニングツールに、利用可能なフォントを一覧表示する機能を追加しました。
- text2image に単語を下線で強調表示する機能を追加しました。
- PDF 出力のための画像処理の効率を向上させました。
- コマンドラインオプション ‘print-parameters’ でリストされている各パラメータの説明を追加しました。
- hOCR 出力にフォント情報を追加しました。
- 複数ページドキュメントのストリーミング入力と出力を有効にしました。
- 多くのバグ修正。
V3.03(rc1)
2014年2月4日
- Tesseract は現在、Leptonica 1.70 以降のバージョンが必要です。
- OpenCL サポートを追加しました(実験的)。
- テキストと TrueType フォントからボックス/tif ファイルペアを生成するための新しいトレーニングツール text2image を追加しました。
- 検索可能なテキストを含む PDF 出力をサポートしました。
- IMAGE クラス全体と image ディレクトリのすべてのコードを削除しました。
- Tesseract 実行可能ファイル: stdout への出力のサポート。stdin からの 1 ページの画像に対する限定的なサポート(特に Windows 上)。
- ドキュメントレベルの処理と hOCR、PDF などのドキュメント形式の出力を行うためのレンダラーを API に追加しました。
- 単語レベルの認識、ビームサーチの大幅なリファクタリング、デッドコードの削除。
- 新しい分類器を追加しやすくするために、分類器をリファクタリングしました。
- グレースケールからの特徴抽出を可能にするために、特徴抽出器を汎化しました。
- 上下添字の処理を改善しました。
- ベースラインの適合を改善しました。
- トレーニングツールに set_unicharset_properties を追加しました。
- 多くのバグ修正。
- より多くのトレーニングソースデータを含めました。
V3.02.02
2012年10月23日
- Tesseract は現在、Leptonica 1.69 以降のバージョンが必要です。
- ResultIterator/PageIterator を ccmain に移動しました。
- ヘブライ語/アラビア語の出力イテレータに右から左/双方向機能を追加しました。
- レイアウト分析/OCR 後処理に段落検出を追加しました。
- トレーニング中の不整合な x 高さと過剰な分割を修正しました。
- 同時多言語機能を追加しました。
- 最上位の単語認識モジュールをリファクタリングしました。
- 実験的な数式検出器を追加しました。
- 入力画像からの解像度の処理を改善しました。
- エラー分析のための Blamer モジュールを追加しました。
- baseapi.h からのインクルードを削除することにより、外部で使用される名前空間をクリーンアップしました。
- デッドメモリ管理コードを削除しました。
- 制御パラメータの制約を整理しました。
- 分類器とトレーニングに ShapeTable のサポートを追加しました。
- クラスプルーナーをリファクタリングしました。
- トレーニングのリークとランダム性を修正しました。
- より良い画像検出、アクセント記号の検出、より良いテキスト行の検出、より良いタブストップの検出のためのレイアウト分析を大幅に改善しました。
- 行の検出と削除を改善しました。
- CJK 用の固定ピッチチョッパーを追加しました。
- 多言語処理を容易にするために、UNICHARSET を WERD_CHOICE に追加しました。
- 内部的にスケールされた画像の問題を修正しました。
- トレーニングデータのソースをより適切に識別するために、tr ファイルの文字列にページとバウンディングボックスを追加しました。
- ヒンディー語 Shiroreka スプリッターの修正。
- 単語バイグラム補正を追加しました。
- スタックメモリの消費量を削減し、いくつかの見にくい typedef を削除しました。
- 新しい統一分類器 API を追加しました。
- 新しいトレーニングエラーカウンターを追加しました。
- dawg リーダーのエンディアンのバグを修正しました。
- C API(Tobias Müller による)
- VS 2008 の新しいソリューション(Tom Powers による)
- チョッパーがチョップを見つけて、その際にアウトラインをどのように操作するかを修正しました。
- その他多くの修正。
V3.01
2011年10月21日
- スレッドセーフ!すべての重要なグローバル変数と静的変数を適切なクラスのメンバーに移動しました。いくつかの制御パラメータはまだグローバルであり、すべてのスレッドに影響を与えるという小さな例外を除いて、Tesseract は現在スレッドセーフです(複数のインスタンスを複数のスレッドで並列に使用できます)。
- アラビア語とヒンディー語向けの新しい実験的な認識器
Cubeを追加しました。Cube は、精度がわずかに向上する代わりに速度が大幅に低下するという犠牲を払って、他のいくつかの言語でも通常の Tesseract と組み合わせて使用できます。Cube のトレーニングモジュールはありません。 Init内のOcrEngineModeは、Cube を制御するためにAccuracyVSpeedを置き換えました。- 特に中国語において、セグメンテーション検索を大幅に改善し、精度と速度を向上させました。
TessBaseAPI::Get*メソッドでは現在提供されていない、Tesseract から完全な結果を取得するためのよりクリーンな方法として、PageIteratorとResultIteratorを追加しました。ETEXT_STRUCTなど、他のすべてのメソッドは非推奨となり、将来削除されます。- トレーニングを容易にするために、ApplyBoxes を完全に書き直しました。現在は、接触/重複しているトレーニング文字を処理でき、新しいボックスファイル形式では文字ボックスではなく単語ボックスを使用できますが、これを使用するには、すでに文字ボックスを使用して言語をブートストラップしている必要があります。「トレーニングデータへの循環依存関係」。
- ページレイアウト分析に自動方向とスクリプト検出を追加しました。
- 多くのデッドコードを削除しました。
- Fixxht モジュールをスケーラブルなデータ駆動型モジュールに置き換えました。
- 出力フォント特性の精度を向上させました。
- 各分類で二重変換を削除しました。
- 最も古い構造体をクラスにアップグレードし、PBLOB を非推奨にしました。
- 非決定的なベースラインの適合を削除しました。
- 中国語向けの固定長の DAWG を追加しました。
- 縦書きテキストの処理を改善しました。
- リーダードットの処理を改善しました。
- テーブル検出を大幅に改善しました。
- いくつかのメモリリークを修正しました。
- 出力テキストのフォントラベルを修正しました。(完璧ではありませんが、以前よりもはるかに改善されました)。
- クリーンアップとその他のバグ修正
- ヒンディー語の特別な処理。
- Microsoft Windows SDK for Windows 7 を使用した VS2010 でのビルドのサポート(Michael Lutz による)
V3.00
2010年9月30日
- スレッドセーフの準備
- TessBaseAPI メソッドを非静的メソッドに変更しました。
- インスタンスデータを保持するためのディレクトリにクラス階層を作成し、コードをクラスに移動し始めました。
- 閾値処理コードを別のクラスに移動しました。
- 主要な新しいページレイアウト分析モジュールを追加しました。
- hOCR 出力を追加しました。
- Leptonicaを主要な画像入出力および処理ライブラリとして追加しました。現時点ではオプションですが、今後のリリースではLeptonicaとのリンクが必須になります。
- 曖昧性テーブルを書き直し、fix_quotesの代わりに明確な置換を可能にしました。
- データファイルを単一ファイルに結合するTessdataManagerを追加しました。
- 一部のデッドコードを削除しました。
- VC++6のサポートを終了しました。テンプレートの使用に対応できません。
- 多くの言語を追加しました。
- ほとんどの関数ヘッダーコメントをDoxygen形式にしました。
V2.04
2009年6月30日
- 移植性向上と一部の「access」マクロの削除のためのパッチを統合しました。
- ビューアからLuaへの依存を削除し、大幅に高速化しました。また、ビューアはLinuxでコンパイルおよび動作するようになりました。Windowsでも事前にビルドされたScrollView.jarを使用することで動作します。
- 以下の問題を修正しました:1, 63, 67, 71, 76, 79, 81, 82, 84, 106, 108, 111, 112, 128, 129, 130, 133, 135, 142, 143, 145, 146, 147, 153, 154, 160, 165, 169, 170, 175, 177, 187, 192, 195, 199, 201, 205, 209。
- これはVC++6をサポートする最後のバージョンです!
- これはLeptonicaなしでコンパイルできる最後のバージョンになる可能性もあります!
- Windows版はデフォルトでstderrに出力するようになり、意味のあるエラーメッセージが表示されないという多くの問題が解決されました。
V2.03
2008年4月22日
2.02は、最終段階での「簡単な」変更により実行できませんでした。2.03はこの問題を修正します。また、Leptonicaのincludeチェックを追加して、より使いやすくしました。
V2.02
2008年4月21日
- クラスタリング、トレーニング、分類器の改良を行いました。
- カンナダ語など、大文字集合言語の国際化を大幅に改良しました。
- コンパイラの警告をいくつか削除しました。
- トレーニングと実行のためのマルチページTIFFサポートを追加しました。
- 新しいJavaベースのビューアと通信するようにグラフィックス出力を更新しました。
- n-bestリストを保存する機能を追加しました。
- より多くのファイルタイプに対応するため、Leptonicaサポートを追加しました。
- Init/Endを安全にするために改良しました。
- 辞書のメモリ使用量を削減しました。
- TessBaseAPIに新しいAPIを追加しました。
- JPEGライブラリとの名前空間の衝突(INT32)を修正しました。
- 新しいコードのWindows向け移植性を修正しました。
- 新しいコードのautoconfシステムを更新しました。
V2.01
2007年8月30日
(使用方法については、下記の2.00のリリースノートも参照してください)
主要な機能変更はありません。バグ修正がいくつか行われています。
- boxファイルリーダーのUTF8入力の問題を修正しました。
- dawgコードの様々な無限ループとクラッシュを修正しました。
- host.hからのconfig_auto.hのインクルードを削除しました。
- unicharset_extractorに自動wctypeエンコーディングを追加しました。
- dawgテーブルがいっぱいのエラーを修正しました。
- tarballからsvnファイルを削除しました。
- tessdllに新しい関数を追加しました。
- 分類結果の最大UTF8文字列を8に増やしました。
- OcropusのためにTessBaseAPIに新しい機能を追加しました。
元の6言語には新しいデータファイルはありません。v2.00のファイルを使用してください。ドイツ語Fraktur(deu-f)とブラジルポルトガル語(por)の新しいデータファイルがあります。
速報 unicharset_extractorに軽微なバグがあります。これはトレーニングにのみ適用されるため、トレーニングを実行する必要がない限り、メインのtarballは問題ありません。トレーニングを実行する必要がある場合は、unicharset_extractor.cppとunicharset_extractor.exeをtesseract-2.01.patch1.tar.gz内のものと置き換えてください。
V2.00
2007年7月18日
(追加の使用方法については、下記の1.04のリリースノートも参照してください)
国際版の最初のリリースです。このバージョンは次の言語を認識します。
- 英語 - eng
- フランス語 - fra
- イタリア語 - ita
- ドイツ語 - deu
- スペイン語 - spa
- オランダ語 - nld
言語コードはISO 639-2に従っています。デフォルトの言語は英語です。別の言語を認識するには
tesseract inputimage outputbase -l langcode
新しい言語でトレーニングするには、TrainingTesseract2を参照してください。今後、より多くの言語が登場する予定です。
このリリースでの変更点のリスト
- 内部文字処理をUTF8に変換しました。
- 6言語でトレーニングしました。
- unicharset_extractor、wordlist2dawgを追加しました。
- boxファイル作成モードを追加しました。
- UNLV回帰テスト機能を追加しました。
- 著作権記号と登録商標記号に関する問題を修正しました。
- extern “C”宣言の問題を修正しました。
- プラットフォーム間での精度の整合性を改善しました。
- VC++ Expressのサポートを追加しました。
警告:Tesseract 2.00は、以前のバージョンよりも多くの互換性テストが行われています。プラットフォーム間での精度の整合性を向上させるための修正も行われています。とは言っても、コードには多くの変更が加えられており、移植性が損なわれている可能性があるため、64ビット版とMac版は以前のように動作しない、またはビルドできない可能性があります。
V1.04
2007年5月15日
Tesseractの開発は現在、Subversionを使用してcode.google.comで行われています(以前はCVSをバージョン管理システムとして、sourceforge.netをホスティングに使用していました)。
Windowsユーザーのみ
Windows用のdllインターフェースを追加しました。これはJetsoftのGlenによる貢献です。dllを使用するには、tessdll.hをインクルードし、tessdll.libをインポートし、tessdll.dllをシステムが見つけられる場所に配置します。dllをテストするための小さなdlltestプログラムもあります。次のように実行します。
dlltest phototest.tif phototest.txt
phototest.tifからのテキストとバウンディングボックス情報を表示します。
Windowsの新機能
このディストリビューションには、すぐに動作する可能性のあるtesseract.exeとtessdll.dllが含まれています!動作させるには、少なくともVC++6バージョンのMFCとCRTが必要なため、保証はありません。(バッテリーは含まれていませんし、インストールシールドももちろんありません。)
makeでビルドするすべての人(つまり、devstudioユーザー以外)にとって重要なメモ
このリリースには、データディレクトリの新しい標準化が含まれています。Tesseractがデータファイルを見つけるには、次のいずれかを行う必要があります。
./configure
make
make install
データファイルを標準の場所に移動するか、
export TESSDATA_PREFIX="directory in which your tessdata resides/"
(または同等のもの)を.profileまたはその他のファイルに設定するか、環境変数を設定するためにsetenvを使用します。ディレクトリは/で終わる必要があることに注意してください。
tesseractとtessdataを同じディレクトリに配置しても、もう動作しません。
すべてのユーザー
多くの名前の衝突を修正しました - 主にSTLとの衝突です。Unicode互換性のための予備的な変更を行いました。新しいデータファイル(unicharset)と他のデータファイルのengへの名前変更が含まれており、異なる言語をサポートします。また、その他の軽微なバグ修正と、64ビット、最新のVisual Studioコンパイラなどに対する移植性の向上も含まれています。
これらの修正に貢献してくれたすべての方々に感謝します。
注:これはおそらく最後の英語のみのリリースです!Windowsの実行ファイルによって配布が膨らむことを、Windows以外のユーザーの方々にはあらかじめお詫び申し上げます。これは、多言語対応によって配布が膨らむため、次のリリースで修正される可能性があります。
V1.03
2007年2月3日
- mftrainingとcntrainingを追加しました。
- グレーとカラーの適応しきい値処理を使用したbaseapiを追加しました。
- 多くのメモリリークを修正しました。
- 適応型分類器の使用の欠如など、いくつかのバグを修正しました。
- グラフィックスコードを排除し、組み込みプラットフォームサポートを追加するためのifdefを追加しました。
- 64ビットビルド、Macビルドを含むいくつかのパッチを組み込みました。
- 精度の軽微な改善を行いました。
V1.02
2006年10月4日
- Aspirinへの依存を削除しました。
- いくつかのApacheライセンスヘッダーの欠落を修正しました。
- $logを削除しました。
V1.01
2006年9月7日
- VC++用にmfcpch.cppとgetopt.cppを追加しました。
- グレースケール画像とlibtiffがない場合の問題を修正しました。
- 使用方法の出力を表示するためにデバッグウィンドウを使用しないようにしました。
- ビッグエンディアンアーキテクチャのinttempの読み込みを修正しました。
- Macのコンパイルに関するいくつかの問題を修正しました。
V1.00
2006年6月17日
Tesseractの最初のオープンソースバージョン!
sourceforge.netでホストされています。CVSはバージョン管理に使用されています。